
Zu diesem Zeitpunkt wissen wir bereits, dass KI-Modelle zum Lernen eine Menge Daten aus zahlreichen Quellen aufnehmen müssen. Unternehmen extrahieren Daten aus Quellen im gesamten Internet wie E-Books, Social-Media-Sites, Video-Sites, Nachrichten-Websites, Blogs und so weiter. Ein Großteil der Daten ist für die Öffentlichkeit kostenlos, aber KI-Unternehmen beziehen auch eine Menge Daten aus Premium-Quellen. Wir sprechen hier von kostenpflichtigen, urheberrechtlich geschützten Inhalten. Für den Durchschnittsmenschen bedeutet das vielleicht nicht viel, aber welche Auswirkungen hat diese Praxis und ist sie gerechtfertigt?
Wir erleben heutzutage einen Wandel in der Branche. Große Nachrichten- und Medienunternehmen unterzeichnen Verträge, die ihre Inhalte an KI-Unternehmen wie OpenAI und Meta übergeben. Das hat die Massen wirklich schockiert, da sich die KI-Technologie negativ auf den Journalismus ausgewirkt hat. Daher ist es ein wenig überraschend, dass so viele Nachrichtenunternehmen ihre Inhalte gerne an KI-Unternehmen weitergeben, um Journalisten weiter überflüssig zu machen.
Die rechtliche Seite
Bei dieser Praxis geht es unter anderem darum, rechtliche Probleme mit Unternehmen zu vermeiden. Nicht allzu lange nach der KI-Explosion fanden wir heraus, woher KI-Unternehmen die Daten hatten, um ihre KI-Modelle zu trainieren. Mehreren großen Unternehmen gefiel es nicht, dass KI-Unternehmen ihre Inhalte aussortierten, und eines der größten Unternehmen war die New York Times. Zum Zeitpunkt des Verfassens dieses Artikels befindet sich die New York Times in einem riesigen Rechtsstreit mit OpenAI. Dieses Unternehmen hat eine Menge urheberrechtlich geschützter Artikel der New York Times gelöscht. Darüber hinaus behauptet die New York Times, dass ChatGPT Teile seiner Artikel wörtlich wiedergibt.
Weitere Klagen wie diese sind im vergangenen Jahr aufgetaucht, und wir erwarten von verschiedenen Unternehmen noch mehr. Dies gilt insbesondere, weil immer mehr Meldungen Aufschluss darüber geben, wie viel Premium-Inhalte KI-Unternehmen für das Training ihrer Modelle aufgewendet haben. Die Leute blicken zurück auf die Datensätze, die einige der größten KI-Modelle zum Trainieren verwendet haben, und stellen fest, dass ein Großteil der Inhalte von kostenpflichtigen Websites stammt.
Die Analyse
Wie bereits erwähnt, werden Berichte veröffentlicht, aus denen hervorgeht, wie viel Premium- und Pay-Walled-Daten-KI-Unternehmen für das Training ihrer KI-Modelle ausgeben. Die News Media Alliance veröffentlichte letztes Jahr einen Bericht, in dem sie uns mitteilte, dass einige der größten Datensätze der Welt eine beträchtliche Menge an Premium-Inhalten verwendeten.
Es stellte sich heraus, dass OpenWebText, die zum Trainieren des GPT-2-Modells von OpenAI verwendeten Datensätze, zu etwa 10 % aus Premium-Inhalten bestanden. Das hört sich vielleicht nicht viel an, aber dieser Datensatz umfasst etwa 23 Millionen Webseiten. Von einem Kuchen mit 23 Millionen Seiten sind also 10 % ein gewaltiges Stück. Darüber hinaus gibt es im Vergleich zum Internet insgesamt nicht allzu viele Premium-Nachrichtenseiten, sodass jeder Prozentsatz über 0,001 % erheblich ist.
Was bedeutet das? Das bedeutet, dass Firmen wie OpenAI nicht nur das Internet durchsuchen und ihre Modelle mit dem füttern, was gerade auftaucht. KI-Unternehmen greifen für ihre Modelle häufig auf Daten von Premium-Websites zurück.
Woher wissen wir das?
Der oben genannte Bericht öffnete die Tür für weitere Nachrichten. Eine aktuelle Analyse von Ziff Davis deutete auf etwas Ähnliches hin; Datensätze, die zum Trainieren wichtiger Modelle verwendet werden, bestehen aus einer großen Menge an kostenpflichtigen Inhalten. Der Bericht von Ziff Davis berücksichtigt jedoch vier Datensätze und verrät etwas über die Absichten der KI-Unternehmen.
Die vier berücksichtigten Datensätze sind Common Crawl, C4, OpenWebText und OpenWebText2. Mehrere KI-Unternehmen nutzen unter anderem diese vier Datensätze, um ihre Modelle zu trainieren.
Common Crawl wurde verwendet, um GPT-3 von OpenAI und LLaMA von Meta zu trainieren. C4 wurde verwendet, um die LaMDA- und T5-Modelle von Google zusammen mit LLaMA zu trainieren. OpenWebText wurde zum Trainieren von GPT-2 und OpenWebText2 zum Trainieren von GPT-3 verwendet. Andere große Modelle verwendeten diese Datensätze höchstwahrscheinlich, die oben genannten Modelle wurden jedoch im Bericht vorgestellt.
Diese Datensätze trainierten also einige ziemlich große Modelle. Offensichtlich sind sie ziemlich veraltet. OpenAI befindet sich derzeit in mehreren Iterationen seiner GPT-4-Serie und Meta läuft auf LLaMA 3, sodass die oben aufgeführten Modelle ihre Blütezeit längst überschritten haben. Wir sollten uns jedoch nicht über die schiere Datenmenge lustig machen, die in diesen Datensätzen vorhanden ist. OpenWebText2 enthält über 17 Millionen Webseiten, während OpenWebText 2 23 Millionen Webseiten enthält. C4 übertrifft sie mit 365 Millionen Webseiten, aber der amtierende Champion ist Common Crawl mit sage und schreibe 3,15 Milliarden Webseiten.
Den Zahlen zufolge dürften GPT-3 und LLaMA die intelligentesten Modelle auf der Liste sein. Das Gegenteil könnte jedoch der Fall sein.
Datensatzpflege
Wenn Sie in der Schule sind, steht Ihr Lehrer nicht einfach sechs Stunden lang vor Ihnen und rattert willkürliche Fakten herunter. Die Informationen, die sie Ihnen mitteilen, müssen vom Lehrer, der Schule und der Schulbehörde kuratiert werden. Aus diesem Grund gibt es Unterrichtspläne und einen einheitlichen Lehrplan. Was hat das mit KI-Modellen zu tun? Nun, KI-Modelle ähneln Menschen mehr als Sie denken.
Wenn Sie ein KI-Modell sind und mit einem Datensatz gefüttert werden, möchten Sie lieber mit hochwertigen und relevanten Informationen gefüttert werden. Daher füllen Unternehmen ihre Modelle nicht immer mit Unmengen an Zufallsdaten. Datensätze werden manchmal bereinigt und kuratiert. Die Bereinigung von Datensätzen ist ein Prozess, der doppelte Daten, Fehler, inkonsistente Informationen, unvollständige Daten und mehr beseitigt. In gewisser Weise wird das Fett reduziert. Die Datensatzkuratierung organisiert den Datensatz, um die Informationen leichter zugänglich zu machen. Dies sind zu starke Vereinfachungen, aber Sie können mit den Hyperlinks mehr lesen.
In jedem Fall werden die Daten durch das Bereinigen und Kuratieren der Datensätze grundsätzlich verarbeitet und aufbereitet, sodass sie für das Modell leichter zu erfassen sind. Dies ähnelt der Art und Weise, wie Ihr Lehrplan so organisiert ist, dass der Schwierigkeitsgrad im Laufe des Jahres allmählich zunimmt.
Lassen Sie uns nun über die Domänenautorität sprechen
Zeit für eine kleine, aber notwendige Tangente. Es gibt noch einen weiteren Aspekt dieses Berichts, und einer davon ist die Domänenautorität. Je höher die Domänenautorität einer Website ist, desto vertrauenswürdiger und seriöser ist sie. Man würde also erwarten, dass eine Website wie die New York Times, ein großes Nachrichtenunternehmen, eine höhere Domain-Autorität hat als eine brandneue Nachrichtenseite, die täglich maximal 10 Aufrufe erhält.
Der Bericht berücksichtigte 15 der Nachrichtenunternehmen mit der höchsten Domain-Autorität. Diese Liste besteht aus „Advance (Condé Nast, Advance Local), Alden Global Capital (Tribune Publishing, MediaNews Group), Axel Springer, Bustle Digital Group, Buzzfeed, Inc., Future plc, Gannett, Hearst, IAC (Dotdash Meredith und andere Abteilungen), News Corp , The New York Times Company, Penske Media Corporation, Vox Media, The Washington Post und Ziff Davis.“
Der Bericht ordnet die Domänenautorität einem 1- bis 100-Punkte-System zu. 100 bedeutet, dass die Site über die größte Domänenautorität verfügt. Die obige Liste besteht aus Websites mit relativ hohen Domain-Autoritäten.
Die Zahlen
Was hat das mit Datensätzen und KI-Modellen zu tun? Nun, lasst uns das alles zusammenfassen. Im Bericht sehen wir eine Aufschlüsselung der vier Datensätze. In der folgenden Grafik sehen wir einen interessanten Trend.
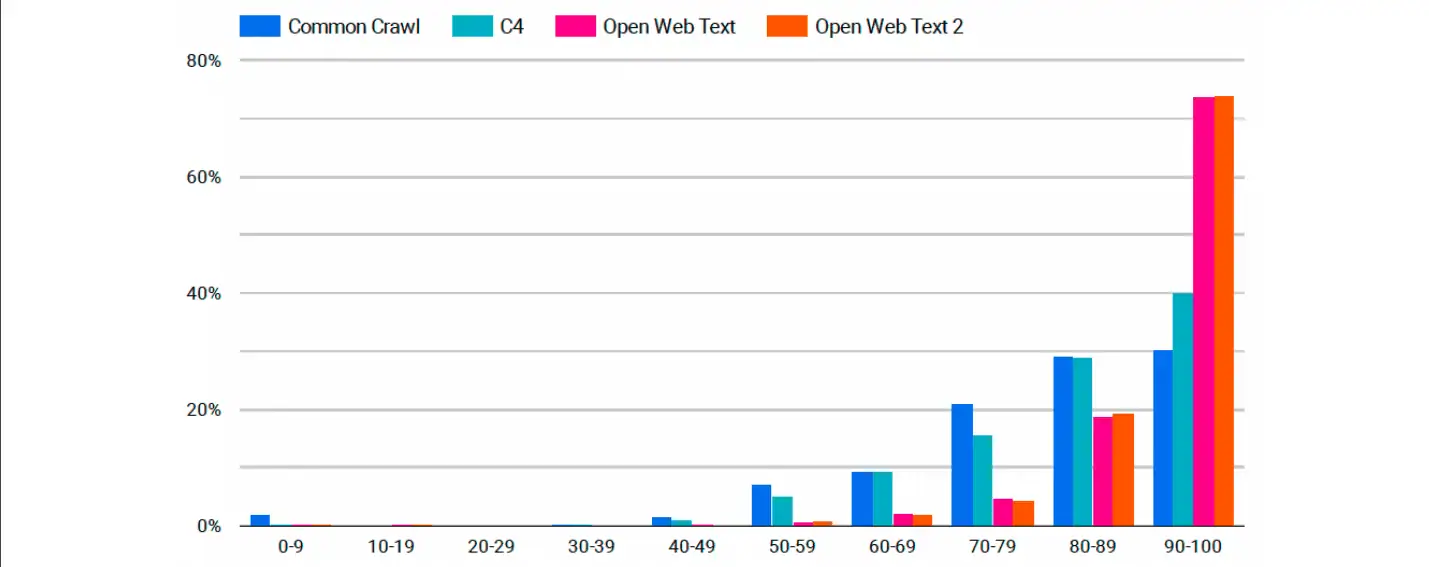
Die X-Achse des Diagramms zeigt die Domänenautoritätswerte unterteilt in 10-Punkte-Intervalle und die Y-Achse zeigt den Prozentsatz der Datenmenge in jedem Satz. Daraus geht hervor, dass etwas mehr als 50 % der Websites im Common Crawl einen Domain-Autoritätswert zwischen 0 und 9 aufweisen. Dieser sinkt stark, wenn die Domain-Autorität steigt. Weniger als 10 % des Datensatzes haben eine Punktzahl von über 10 Punkten, und das gilt auch für den Rest des Diagramms.
Beim Übergang zu C4 sind die Ergebnisse nicht viel besser. Etwa 20 % der Websites haben einen Domain-Score zwischen 10 und 20 Punkten. Dann fällt es auch deutlich ab. C4 bleibt für den Großteil des Diagramms konstant höher als Common Crawl.
Wenn wir uns jedoch die beiden OpenWebText-Datensätze ansehen, sehen wir eine dramatische Veränderung. Tatsächlich sehen wir genau das Gegenteil! Beide Modelle beginnen in der Grafik an einer ähnlichen Stelle mit Werten von 0 bis 9, steigen aber mit steigenden Domänenautoritätswerten stetig an. Mehr als 30 % der OpenWebTexts-Daten stammten von Websites mit Domänenautoritätswerten zwischen 90 und 100. Was OpenWebText 2 betrifft, bestehen etwa 40 % dieses Datensatzes aus Websites mit Domänenautoritätswerten zwischen 90 und 100.
Nur die Premiumseiten
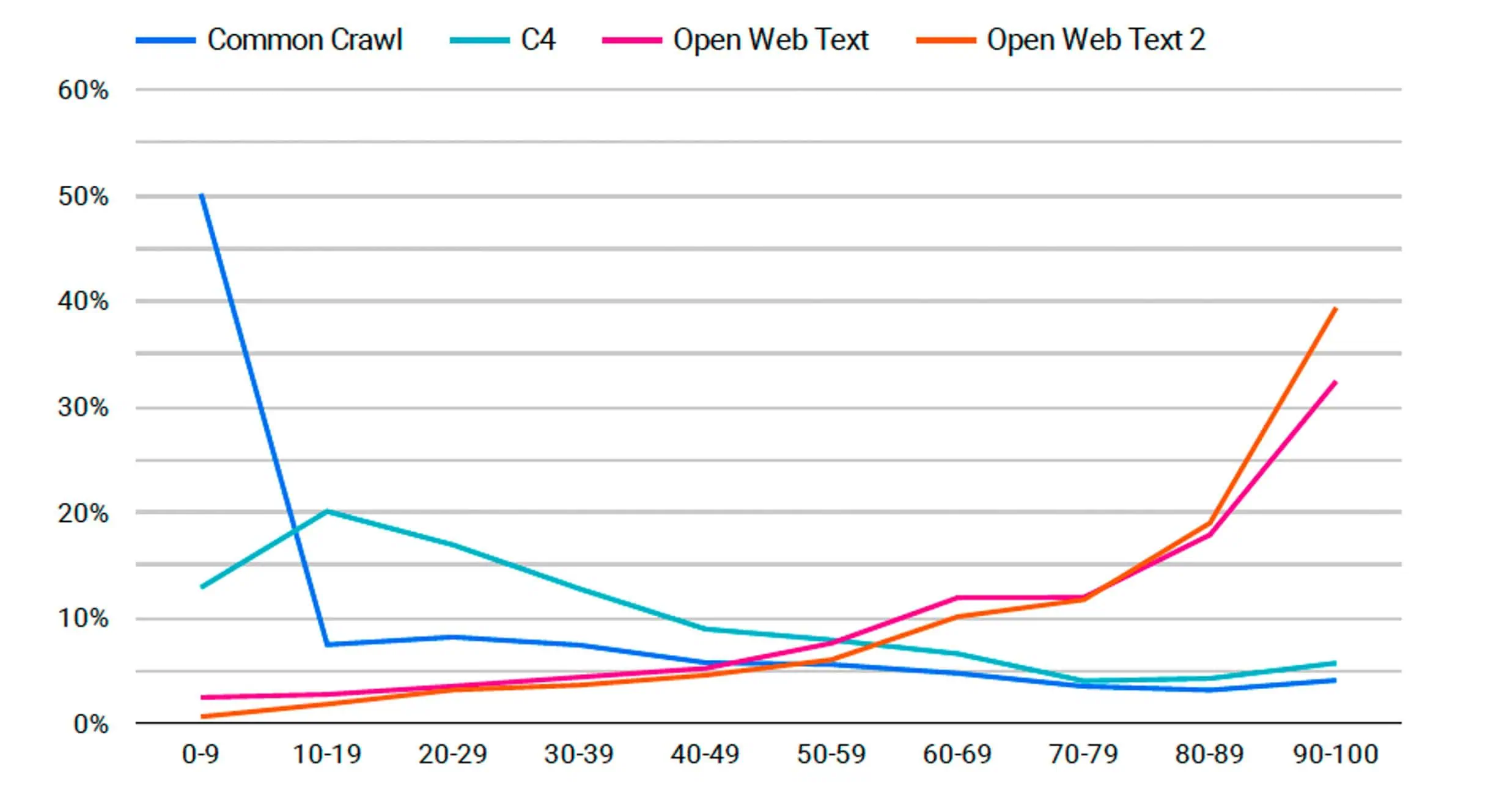
Hier ist eine Grafik, die ähnliche Daten zeigt. Allerdings werden hier nicht die Daten aller erfassten Websites angezeigt, sondern nur die Daten der oben genannten Premium-Websites.
Unten finden Sie eine Grafik, die jede der oben genannten Veröffentlichungen zeigt und zeigt, wie häufig sie in den einzelnen Datensätzen verwendet wurde. Wir sehen, dass der Prozentsatz bei beiden OpenWebText-Modellen sprunghaft ansteigt, aber diese beiden Modelle verfügen über wesentlich weniger Daten, sodass es für eine Quelle einfacher ist, einen höheren Prozentsatz zu erreichen.
Hier ist der Schock
Wir sehen also, dass in den OpenWebText-Datensätzen mehr qualitativ hochwertige Website-Daten vorhanden sind, aber hier ist der Clou. Erinnern Sie sich, wie wir über die Bereinigung und Kuratierung von Datensätzen gesprochen haben? Dieser Prozess nimmt die rohen und ungefilterten Daten und verarbeitet sie. Nun, im Bericht wurden Common Crawl und C4 weder bereinigt noch kuratiert. Die beiden OpenWebText-Datensätze waren. Das bedeutet, dass es sich bei den Datensätzen mit dem höheren Volumen an Premium-Inhalten zufällig um diejenigen handelt, die von Menschenhand berührt wurden.
Dies deutet darauf hin, dass KI-Unternehmen speziell auf Premium-Daten abzielen. Bis zu diesem Zeitpunkt gingen wir davon aus, dass diese Unternehmen sich dafür entschieden haben, Websites einfach zu crawlen und so viele Daten wie möglich in ihre Modelle zu laden, ohne darauf zu achten, woher sie kommen. Die Realität sieht jedoch so aus, dass viele dieser Unternehmen möglicherweise gezielt nach Inhalten suchen, die sie nicht verwenden sollten.
Dieser Bericht zeigt, dass es sich bei einem Großteil der zum Trainieren der OpenAI-Modelle verwendeten Inhalte um Paywall-Inhalte handelt. Die Frage ist also: Wie viele andere Datensätze werden verarbeitet, um Premium-Daten zu bevorzugen?
Kann es gerechtfertigt sein, dass KI-Unternehmen Premium-Daten nutzen?
Oberflächlich betrachtet scheinen die Unternehmen im Unrecht zu sein, aber wenn man etwas tiefer in die Materie eintaucht, beginnt die Grenze zwischen richtig und falsch zu verschwimmen. Wir wissen um die rechtlichen Auswirkungen. KI-Unternehmen überschreiten ihre Grenzen, wenn sie ihre Modelle auf kostenpflichtigem Material trainieren. Abgesehen davon, dass diese Unternehmen in einigen Fällen Teile von kostenpflichtigen Inhalten wörtlich reproduzieren, stehlen sie Daten, um Modelle zu trainieren, die diese Unternehmen aus dem Geschäft drängen. Das ist ziemlich durcheinander.
Dieses Gespräch hat jedoch zwei Seiten. Tatsache ist, dass es KI-Modelle gibt und niemand etwas dagegen tun kann. Sie liefern Antworten auf unsere Fragen, unterrichten uns usw. Darüber hinaus sind diese KI-Tools bereit, in einigen ziemlich wichtigen und unterbesetzten Bereichen wie Medizin und Bildung eingesetzt zu werden. Wenn sie zu Inhalten aus dem Internet geschult werden sollen, ist es am besten, sie zu qualitativ hochwertigen Inhalten zu schulen.
Auch wenn es schwierig ist, zuzugeben, dass diese Praxis einen gewissen Nutzen haben könnte, werden immer mehr Teile unseres Lebens in irgendeiner Weise von KI berührt. Ehrlich gesagt wäre es besser, Modelle zu verwenden, die auf hochwertigen Daten trainiert wurden, als Modelle, die auf was auch immer trainiert wurden. Ein Großteil der Bevölkerung mag den Vormarsch der KI nicht, aber niemand kann den Fortschritt aufhalten. Die KI wird die Oberhand gewinnen, daher kann es das kleinere von zwei Übeln sein, die Modelle auf qualitativ hochwertigere Inhalte zu trainieren.
Reicht das aber?
Rechtfertigt dies die Verwendung von kostenpflichtigen Inhalten? Eines der schlimmsten Dinge in jeder Branche ist es, wenn ein großes Unternehmen einfach tun kann, was es will. Würden Sie Ihrem 8-Jährigen allein in einem unbewachten Süßwarenladen vertrauen? Wenn kein Personal da ist, das es am Aushungern hindert, kommt Ihr Kind natürlich mit Bauchschmerzen nach Hause.
Die Rechtfertigung, dass Unternehmen heimlich Pay-Walling nutzen, gibt ihnen im Grunde genommen freie Hand, so viele Daten wie möglich zu verschlingen, ähnlich wie das Kind. Es gewährt ihnen im Grunde einen Hallenpass, um Daten von anderen kostenpflichtigen Diensten frei zu beziehen. Die im Internet existierenden Unternehmen müssen sich leider an die Regeln des Internets halten; Regel Nr. 1 besagt, dass alle Websites gecrawlt werden und niemand etwas dagegen tun kann.
Die Berichte von Ziff Davis und der News Media Alliance zeigen, dass mehrere KI-Unternehmen wissentlich Daten aus Premium-Publikationen abgeschöpft und dies nicht zur Kenntnis genommen haben. Unternehmen reichen Klagen ein, was sie zu Recht tun sollten, denn es ist nicht abzusehen, wie viele ihrer Daten in denselben Chatbots gespeichert sind, die Journalisten die Jobs stehlen.