
Für Millionen von uns ist die Interaktion mit KI -Chatbots zu einer täglichen Routine geworden. Wir stellen Fragen, Brainstorming -Ideen, Entwürfe von E -Mails und teilen manchmal, vielleicht unwissentlich vertrauliche Informationen. Es gibt ein unausgesprochenes Verständnis, dass es für immer verschwunden ist, wenn wir einen Chat löschen. Aber eine kürzlich in der Begründung von Openai, dem Unternehmen hinter Chatgpt, involvierte Gerichtsgerichtsbeschlüsse hat versehentlich den Vorhang für diese Annahme zurückgezogen. Diese Entwicklung zeigte eine Realität, dass viele Benutzer möglicherweise beunruhigend finden: die Illusion der Privatsphäre in AI -Interaktionen oder Chats.
Diese Offenbarung ergibt sich aus einem legalen Kampf zwischen Openai und der New York Times. Bereits 2023 reichte die Times eine Urheberrechtsverletzungsklage ein. Der Verlag behauptete, OpenAI habe seine riesige Fülle von urheberrechtlich geschützten Artikeln illegal benutzt, um seine leistungsstarken KI -Modelle auszubilden. Im Rahmen des Rechtsverfahrens hat ein Bundesgericht kürzlich eine umfassende Richtlinie ausgestellt: OpenAI muss die Protokolle jedes einzelnen ChatGPT -Gesprächs auf unbestimmte Zeit bewahren, einschließlich derjenigen Benutzer, die glaubten, sie hätten gelöscht.
Die schockierende Reihenfolge: Löschen bedeutet nicht weg
Das Drücken der Schaltfläche „Löschen“ lässt Ihre Chats nicht im digitalen Äther verschwinden. Nun, sie werden Ihnen nicht mehr zur Verfügung stehen, aber sie werden in der Datenbank von Openai stehen. Das ist der Kern des COO von „Nightmare“ Openai, Brad Lightcap, beschrieben. In der Gerichtsbeschließung wird gefordert, dass OpenAI alle Benutzer -Chat -Protokolle und API -Client -Inhalte ohne Cutoff -Datum beibehalten. Der Richter gibt an, dass die Maßnahme darauf abzielt, eine mögliche Löschung von Beweisen zu verhindern, die für den Urheberrechtsstreit relevant sind. Zu diesem Zeitpunkt scheint es wichtig zu sein, sich daran zu erinnern, dass Openai zugegeben hat, potenzielle Beweise in derselben NYT -Klage versehentlich gelöscht zu haben.
Jane Doe, Datenschutzberaterin bei Cybersecure LLP, sagte: “Diese Richtlinie ist beispiellos und setzt einen gefährlichen Präzedenzfall für die Autonomie der Benutzer -Autonomie. ““ “Unternehmen benötigen klare Regeln, die die Entdeckungsbedürfnisse mit grundlegenden Datenschutzrechten ausgleichen«, Fügten sie hinzu.
Die IA-fokussierte Firma legt diese Entscheidung aktiv ein. Das Unternehmen argumentiert vehement, dass eine solche Reihenfolge eine wesentliche Verletzung der Privatsphäre der Benutzer darstellt. Es widerspricht auch direkt mit ihren erklärten Datenschutzverpflichtungen. Sie verweisen auch auf die immense technische und logistische Belastung, solche kolossalen Datensätze auf unbestimmte Zeit zu speichern. Es ist ein legales Gefecht, das unerwartet zu einer „Raucherwaffe“ geworden ist, die Datenerfassungspraktiken der breiteren KI -Branche aufdeckt und die Vorstellung davon in Frage stellt, was „privat“ im Zeitalter der generativen KI wirklich bedeutet.
Inbal Shani, Chief Product Officer bei GitHub, ist auch nicht mit dem Ansatz einverstanden, die Daten der Benutzerinteraktion mit AI -Plattformen auf unbestimmte Zeit zu halten. “Daten, die zur Ausbildung von KI verwendet werden, sollten ihre rechtliche oder ethische Haltbarkeit nicht überleben. “ sagte sie. „Unternehmen benötigen automatisierte Systeme, um Daten zu löschen oder zu anonymisieren, insbesondere wenn diese wiederverwendet oder wiederverwendet werden«, Fügte Shani hinzu.
Die Realität der Datenerfassung: Ein genauerer Blick auf das, was Chatbots sammeln
Wenn OpenAI jetzt gezwungen ist, selbst „gelöschte“ Chats zu behalten, wirft dies die Frage auf: Wie viel unserer Daten sammeln diese KI -Chatbots zunächst? Während der Gerichtsbeschluss in diesem Zusammenhang spezifisch ist, fordert sie eine umfassendere Prüfung der Branche auf.
Laut Untersuchungen von Surfshark, einem Cybersicherheitsunternehmen, variiert die Landschaft der AI -Chatbot -Datenerfassung erheblich. Das Gesamtbild schlägt jedoch einen großen Appetit auf Benutzerinformationen vor:
- Meta AI: Berichten zufolge sammelt Berichten zufolge die meisten Benutzerdaten unter den beliebten Chatbots und sammeln erstaunliche 32 von 35 möglichen Datentypen. Dies umfasst Kategorien wie präzisen Standort, Finanzinformationen, Gesundheits- und Fitnessdaten sowie andere sensible persönliche Details.
- Google Gemini: Sammelt 22 eindeutige Datentypen, die auch präzise Standortdaten, Kontaktinformationen, Benutzerinhalte sowie Such- und Browserverlauf enthalten.
- CHATGPT (OpenAI): Erfasst weniger Typen im Vergleich zu den anderen bei 10 verschiedenen Datentypen. Diese enthalten typischerweise Kontaktinformationen, Benutzerinhalte, Kennungen, Verwendungsdaten und Diagnose. Insbesondere schlägt die Analyse von Surfshark darauf hin, dass ChatGPT die Verfolgung von Daten oder die Verwendung von Werbung in der App von Drittanbietern vermeidet.
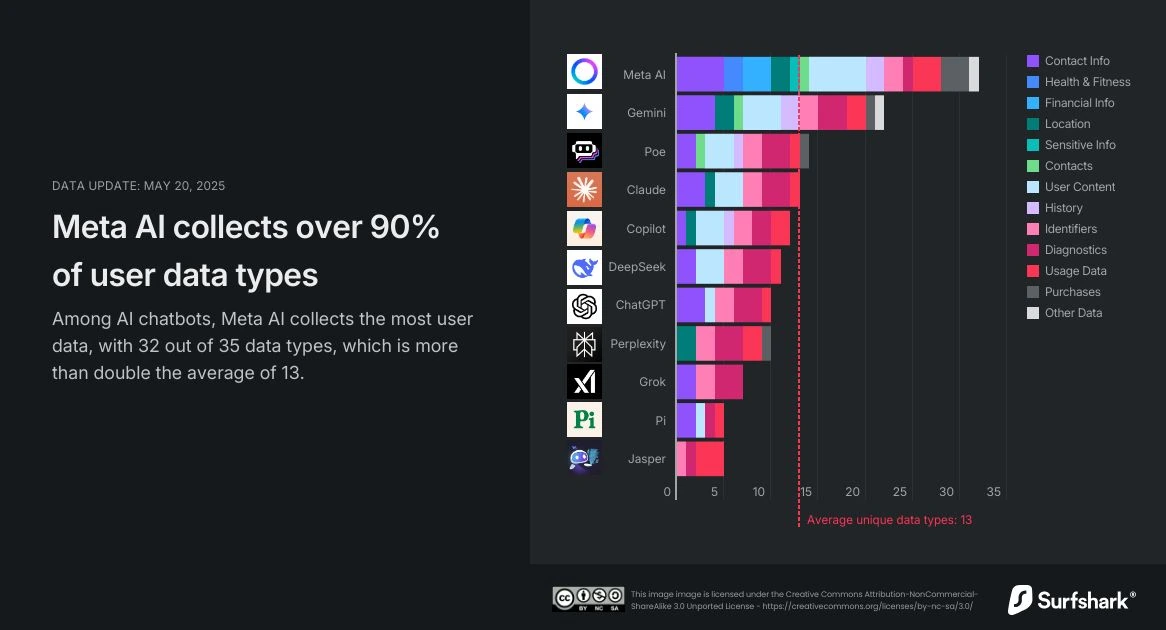
Dieser Vergleich zeigt ein kritisches Spektrum der Datenerfassung. Während einige Unternehmen möglicherweise weniger sammeln, ist das bloße Volumen und die Art von Daten, insbesondere sensible Informationen, die mit Ihren KI -Interaktionen verbunden werden können. Die Aufsichtsbehörden nehmen diese Realität bereits zur Kenntnis. Zum Beispiel hat Italiens Privacy Watchdog kürzlich Replika AI mit einer Geldstrafe von 5 Millionen Euro für schwerwiegende DSGVO -Verstöße im Zusammenhang mit Benutzerdaten geschlagen. In diesen Fällen wird ein globaler Vorstoß auf eine größere Rechenschaftspflicht und Transparenz bei der Behandlung von KI hervorgehoben.
Ein gefährlicher Präzedenzfall: das Vertrauen erodieren und die Privatsphäre neu definieren
Die OpenAI -Gerichtsbeschließung setzt einen gefährlichen Präzedenzfall nicht nur für Openai, sondern auch für die gesamte KI -Branche. Es erschüttert die bequeme Illusion, dass Benutzergespräche kurzlebig oder wirklich „gelöscht“ sind. Für Benutzer bedeutet dies, dass sensible Informationen, persönliche Gedanken oder private Fragen, die mit einem AI -Chatbot geteilt werden, auf einem Server auf unbestimmte Zeit existieren könnten. Sie könnten also unter rechtlicher Zwang potenziell zugänglich sein. Dies könnte zu einem erschreckenden Effekt führen, bei dem Benutzer sich selbst zensierten oder zögern, sich mit KI für sensible Themen zu beschäftigen, das Nutzen zu untergraben und diese Tools zu vertrauen, die aufbauen sollen.
Sam Altmans „KI -Privileg“: Ein Aufruf zur Vertraulichkeit
Die „Angst“, Daten mit KI -Chatbots wie ChatGPT zu teilen, könnte auch Opens Vision für diese Art von Plattformen untergraben. In Anbetracht dieser Privatsphäre hat Sam Altman, der CEO von OpenAI, ein überzeugendes Argument für das geäußert, was er als „KI -Privilegien“ bezeichnet. Altman ist der Ansicht, dass Interaktionen mit KI schließlich mit dem gleichen Grad an Vertraulichkeit und Schutz wie Gespräche zwischen einem Arzt und einem Patienten oder einem Anwalt und Mandanten behandelt werden sollten. Er schlug sogar „Ehegatten Privilegien“ als eine angemessenere Analogie zur Intimität einiger KI -Interaktionen vor.
Dieses Konzept ist nicht nur theoretisch; Es ist eine direkte Reaktion auf die neuen Realitäten, die durch die Klage entlarvt werden. Altmans Forderung nach „KI-Privilegien“ spiegelt ein wachsendes Bewusstsein in der Branche wider, dass die derzeitigen rechtlichen und ethischen Rahmenbedingungen schlecht ausgestattet sind, um die durch die Konversations-KI gestalteten einzigartigen Datenschutzherausforderungen zu bewältigen. Er hofft, dass die Gesellschaft dieses Problem umgehend anspricht und die tiefgreifenden Auswirkungen auf das Benutzervertrauen und die Nützlichkeit von KI anerkennt.
Praktische Schritte, die die Leser jetzt unternehmen können
Was können Sie angesichts dieser Enthüllungen tun, um Ihre Privatsphäre bei der Interaktion mit KI -Chatbots zu schützen?
- Beachten Sie sensible Daten: Vermeiden Sie es, hochempfindliche persönliche, finanzielle, gesundheitliche oder vertrauliche Informationen mit einem AI -Chatbot zu teilen. Angenommen, alles, was Sie tippen, könnte beibehalten werden.
- Überprüfen Sie die Datenschutzrichtlinien (aber bleiben skeptisch): Unternehmen haben Datenschutzrichtlinien, in denen die Datenbearbeitung beschrieben wird. Denken Sie jedoch daran, dass Gerichtsbefehle die Datenerhaltung erzwingen können und möglicherweise die Standard -Löschrichtlinien überschreiben.
- Verwenden Sie „Gast“ oder „Inkognito“ -Modi: Wenn ein KI -Dienst vorübergehende oder inkognito -Modi (wie Chatgpts „Chat History & Training“ -Wechsel bietet, verwenden Sie sie. Verstehen Sie jedoch, dass „vorübergehend“ häufig „aus Ihrer sichtbaren Geschichte gelöscht“ bedeutet, nicht unbedingt dauerhaft aus allen Backend -Systemen gelöscht wurde.
- Überprüfen Sie regelmäßig die Kontoeinstellungen: Überprüfen Sie regelmäßig die Kontoeinstellungen Ihres KI -Chatbots auf Datenbindung oder Löschoptionen und üben Sie sie aus, falls dies verfügbar ist.
- Bleiben Sie auf dem Laufenden: Beobachten Sie Nachrichten und Datenschutzdiskussionen rund um die KI. Die regulatorische Landschaft entwickelt sich schnell weiter.
Reaktionen der Industrie, rechtlichen und gesetzgeberischen
Die OpenAI -Gerichtsbeschließung hat zweifellos Wellen durch die gesamte KI -Branche geschickt. Während keine weiteren großen KI -Unternehmen öffentlich sofort als Reaktion auf diese Anordnung (über bestehende Datenschutzverpflichtungen) unmittelbar direkte Richtlinienänderungen angekündigt haben, wird die Gefahr ähnlicher rechtlicher Mandate mit ziemlicher Sicherheit zu internen Überprüfungen der Datenerhaltungsrichtlinien und der Lobbyarbeit für klarere Vorschriften führen.
Experten für das Datenschutzrecht sagen eine erhöhte Prüfung vor. Die Europäische Union mit ihrer strengen DSGVO (allgemeine Datenschutzverordnung) und dem Pionier-AI-Gesetz (das KI-Entwicklern einen risikobasierten Rahmen auferlegt) führt die Anklage an. Es wird erwartet, dass andere Nationen und Regionen dem Beispiel folgen. Dies könnte möglicherweise zu umfassenderen Datenschutzgesetzen des Bundes in den USA führen, die sich speziell mit AI befassen. Der Rechtsstreit selbst, bei dem ein Bundesrichter bereits die Kernvorschriften für Urheberrechte zulässt, wird die Zukunft der Beziehung der KI zu geistigem Eigentum und Benutzerdaten prägen.
Der Vorfall dient als Weckruf: Während KI unglaubliche Bequemlichkeit bietet, können die wahren Kosten für „freie“ KI-Antworten ein grundlegendes Überdenken unserer digitalen Privatsphäre und die unsichtbaren Repositorys unserer Gespräche beinhalten. Wenn KI in unser Leben tiefer integriert wird, wird die Nachfrage nach Transparenz, robuste Datenschutzsicherung und ein klares Verständnis der Datenbindung nur lauter werden.